企业级私有知识库建设:RAG 技术的实战应用
在企业环境中,AI 工具面临一个核心挑战:如何理解和使用企业内部的私有技术资产?
通用 AI 模型虽然掌握了大量公开技术知识,但对企业内部的组件库、设计规范、最佳实践等一无所知。这篇文章分享我使用 RAG(检索增强生成)技术解决这个问题的实践经验。
前置名词解释
-
Chunk: 将文本(或其它数据)切分为每一段数据,是一种数据切片的方法。 -
Embedding: 将每个 chunk 转换为向量,是一种将高维空间的数据(文字、图片等)转换为低维空间的表示方法,后续可以通过匹配向量之间的余弦相似度来实现语义检索。 -
Vector Database: 向量数据库,用于存储 Embedding 和原始 Chunk 的数据库(注意:某些 Vector Database 只支持存储 Embedding,需要自行来建立 Embedding 和原始 Chunk 之间的映射关系)。
构建 RAG 知识库的过程
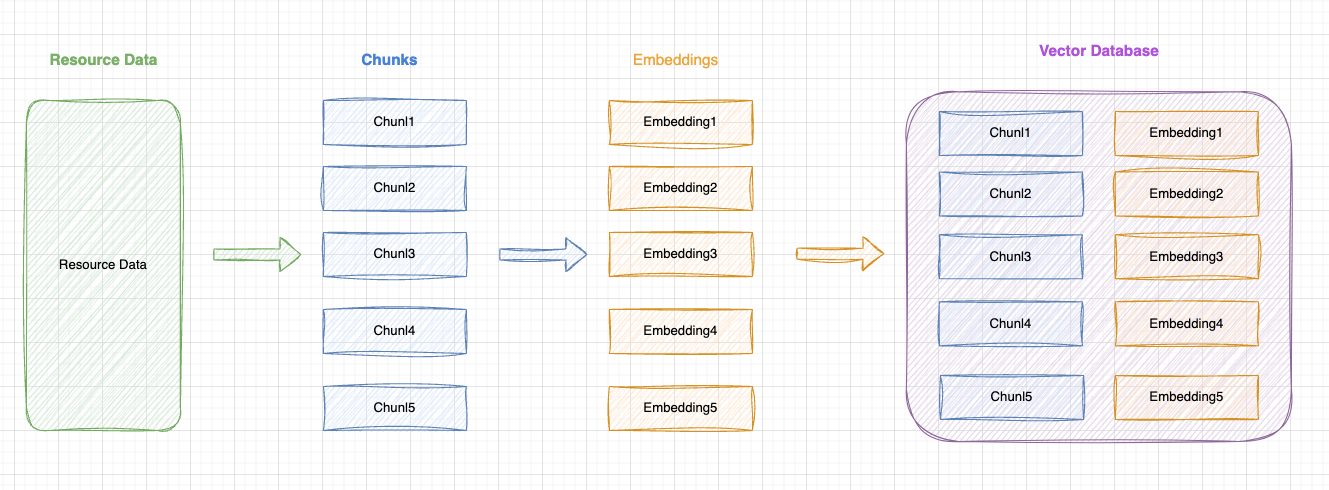
1. 原始数据(Resource Data)
从各种来源收集原始数据,比如公司私有组件库的文档文本。
数据来源包括:
- 组件库的 API 文档
- 使用示例和最佳实践
- 设计规范和样式指南
- 代码注释和说明文档
2. 分块(Chunking)
将资源数据细分为更小的块,称为 Chunk。
分块策略:
- 按组件进行分块
- 按功能模块分块
- 按文档章节分块
- 控制每个 chunk 的长度(通常 500-1000 tokens)
3. 向量化(Embedding)
将每个 Chunk 转换为向量表示,便于后续根据向量进行语义相似度匹配。
Embedding 模型选择:
- OpenAI
text-embedding-ada-002 - 中文优化的模型如
m3e-base - 多语言模型
multilingual-e5-large
4. 存储至向量数据库
将所有的 Chunk 和 Embedding 一一对应存储在向量数据库中,用于后续向量匹配检索出原始的 Chunk 数据。
常用向量数据库:
- Pinecone: 云端托管,易于使用
- Qdrant: 开源,性能优秀
- Chroma: 轻量级,适合开发测试
- Weaviate: 功能丰富,支持混合搜索
RAG 检索过程示例

实际检索流程
-
用户输入问题
帮我生成一个table,包含姓名、年龄、性别。 -
问题向量化
- 将用户问题转换为向量表示
- 使用与构建知识库相同的 Embedding 模型
-
相似度匹配检索(Retrieval)
- 将用户需求的向量和向量数据库中的向量进行相似度匹配
- 检索出相似度高的数据源
- 通常返回 Top-K 个最相关的 chunks
-
增强提示(Augmented)
- 将检索出的数据源和用户需求的问题组合
- 构建包含上下文信息的完整提示词
-
生成回答(Generation)
- 将增强后的提示词输入给大模型
- 生成基于私有组件库的代码
实际应用示例
// 用户问题
const userQuestion = "帮我生成一个table,包含姓名、年龄、性别";
// 检索到的相关组件文档
const retrievedDocs = [
{
component: "CustomTable",
api: "columns: TableColumn[], data: any[]",
example: `
<CustomTable
columns={[
{ key: 'name', title: '姓名' },
{ key: 'age', title: '年龄' },
{ key: 'gender', title: '性别' }
]}
data={userData}
/>
`
}
];
// 增强后的提示词
const enhancedPrompt = `
基于以下组件文档,${userQuestion}
可用组件:
${retrievedDocs.map(doc => `
组件名:${doc.component}
API:${doc.api}
示例:${doc.example}
`).join('\n')}
请生成符合上述组件库规范的代码。
`;注意: 嵌入和向量数据库只是一种特定的检索方法,用于实现语义搜索,而不是 RAG 的必要组件,你也可以通过其它方式来实现检索,比如传统的关键词搜索、混合检索等。
RAG 系统的优化策略
1. 数据质量优化
- 清洗数据:移除无关信息,保持文档结构清晰
- 标准化格式:统一组件文档的格式和结构
- 丰富示例:为每个组件提供多样化的使用示例
2. 检索精度优化
- 混合检索:结合语义检索和关键词检索
- 重排序:对检索结果进行二次排序
- 动态 K 值:根据查询复杂度动态调整返回结果数量
3. 生成质量优化
- 提示词工程:优化增强提示词的结构和内容
- 上下文窗口管理:合理控制输入长度
- 结果验证:对生成的代码进行语法和逻辑验证
下一步实践
了解了 RAG 的基本原理,接下来我们将基于 RAG 技术,来实现私有组件库的代码生成。
具体实践将包括:
- 方案一:基于开源知识库平台接入私有组件库
- 方案二:基于 LlamaIndex 接入私有组件库
- 方案三:自定义 AI Agent Workflow 接入私有组件库
每种方案都有其适用场景和优缺点,我们将在后续文章中详细介绍和实践。
通过 RAG 技术,我们可以让 AI 真正理解企业的私有组件库,生成符合企业规范的高质量代码,这是 AI 赋能企业级前端开发的关键一步。
Last updated on